The post was first published here
For the last couple of years, I have been working with various HTTP APIs. Quite often those APIs were not the public and only made available to partner companies. Also, I have seen APIs developed by fellow developers and participated in the development of several APIs myself. Quite often these APIs have a design flaw which makes it harder to create reliable integrations using the API.
The problem I’m talking about is duplicate resource creation on errors. It’s essential when resource creation is bound to critical real-world operations such as payments.
Let’s take Paypal’s Create Payment API as an example: when you create a new payment resource (by issuing a POST request to /v1/payments/payment), PayPal charges the user immediately. If the transaction is successful, you get back the status code 201 Created complemented with the payment id. That means that if you encounter network issues while sending this request, there is no easy way to tell if the payment was successful or not because you don’t know the payment id. What’s worse is that if you have an automatic retry on network errors, you will undoubtedly charge your users twice at some point.
Of course, this is a known problem with the API and PayPal offers a solution to it. See How to avoid duplicate payments? You can use the header PayPal-Request-Id (not documented at the Payments API page though), or you can misuse the invoice number to de-duplicate the requests. But does the solution have to be so complicated? Both ways are not user-friendly: the consumer needs to have a reliable mechanism for generating request IDs so that duplicate requests have the same request ID; in the second case, what if you need to support multiple payments per one invoice? There might be a more elegant solution.
Solving duplicate resource creation with POST/PUT resource creation
You can easily avoid the problem if the POST request would do nothing more than a database entry and generation of the resource id. The flow is like this:
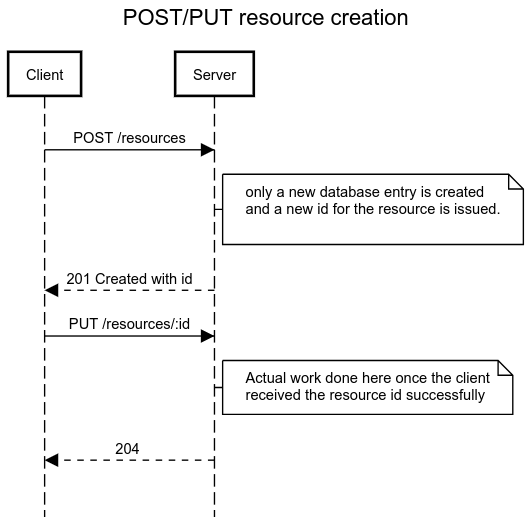
With this flow, it’s easy to retry requests when network failures happen. If you retry the POST request, it would just result in a duplicate empty resource. If you retry the PUT request, you are safe because PUT request is idempotent.
I find the pattern of POST/PUT creation to be more elegant despite the fact that it requires two requests to create a resource entirely. You may not like this approach, but my point is that you should support some way to de-duplicate POST requests if they result in significant real-world consequences. If you provide no such mechanism, your API is hardly suitable for stable and reliable integration.
Thanks for reading and hope it was helpful. Follow me on Twitter and share the problems you encountered with APIs and how you solved them.